
Support Vector Machines (SVM) are a cornerstone of machine learning, renowned for their ability to handle both classification and regression tasks with remarkable effectiveness. In this comprehensive guide, we’ll delve into what makes SVMs so powerful, exploring their key concepts, working mechanisms, advantages, and practical applications. We’ll also include illustrative diagrams to enhance understanding.
Key Concepts of SVM
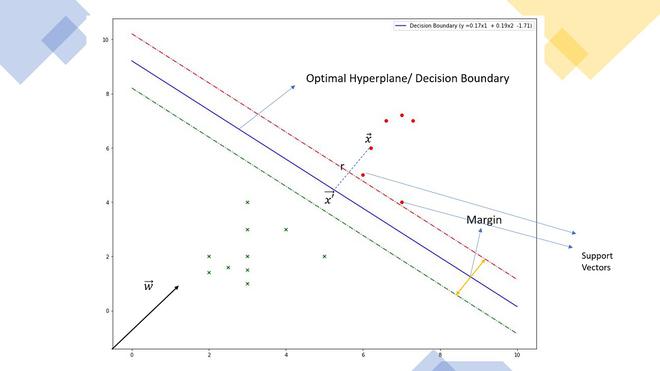
- Hyperplane
- A hyperplane in an n-dimensional space is a flat affine subspace of dimension n-1 that separates the space into two distinct parts.
- Diagram: [Illustrate a 2D plane with a line separating two classes]
- Support Vectors
- These are the data points closest to the hyperplane and are critical in defining the position and orientation of the hyperplane.
- Diagram: [Show data points with a line, highlighting the support vectors]
- Margin
- The margin is the distance between the hyperplane and the nearest data points from either class. SVM aims to maximize this margin to improve the classifier’s robustness.
- Diagram: [Illustrate a margin with support vectors and hyperplane]
How SVM Works
- Linear SVM
- For linearly separable data, SVM finds a straight hyperplane that separates the classes. The algorithm identifies the support vectors and maximizes the margin between the support vectors and the hyperplane.
- Diagram: [Illustrate a linear hyperplane separating two classes]
- Non-linear SVM
- When data is not linearly separable, SVM employs the kernel trick to transform the data into a higher-dimensional space where a linear separator can be found.
- Diagram: [Show transformation using a kernel trick from non-linear to linear separation]
Steps in the SVM Algorithm
- Training:
- Compute the hyperplane that best separates the data by solving a convex optimization problem.
- Identify the support vectors.
- Maximize the margin.
- Diagram:
-

- Prediction:
- Use the hyperplane to classify new data points based on which side of the hyperplane they fall on.
- Diagram:
-
Advantages of SVM
- Effective in high-dimensional spaces: SVM performs well when the number of dimensions exceeds the number of samples.
- Memory efficient: Only a subset of training points (support vectors) is used in the decision function.
- Versatility: Different kernel functions can be specified for the decision function, allowing flexibility in handling various types of data.
Disadvantages of SVM
- Not suitable for large datasets: SVM can be computationally intensive and slow with large datasets.
- Choice of kernel: Performance heavily depends on the appropriate selection of the kernel and its parameters.
- Difficulty with noisy data: SVM is sensitive to noisy data and overlapping classes.
Applications of SVM
- Text and hypertext categorization
- Image classification
- Bioinformatics (e.g., protein classification)
- Handwriting recognition
Diagrams
- Hyperplane in 2D Space
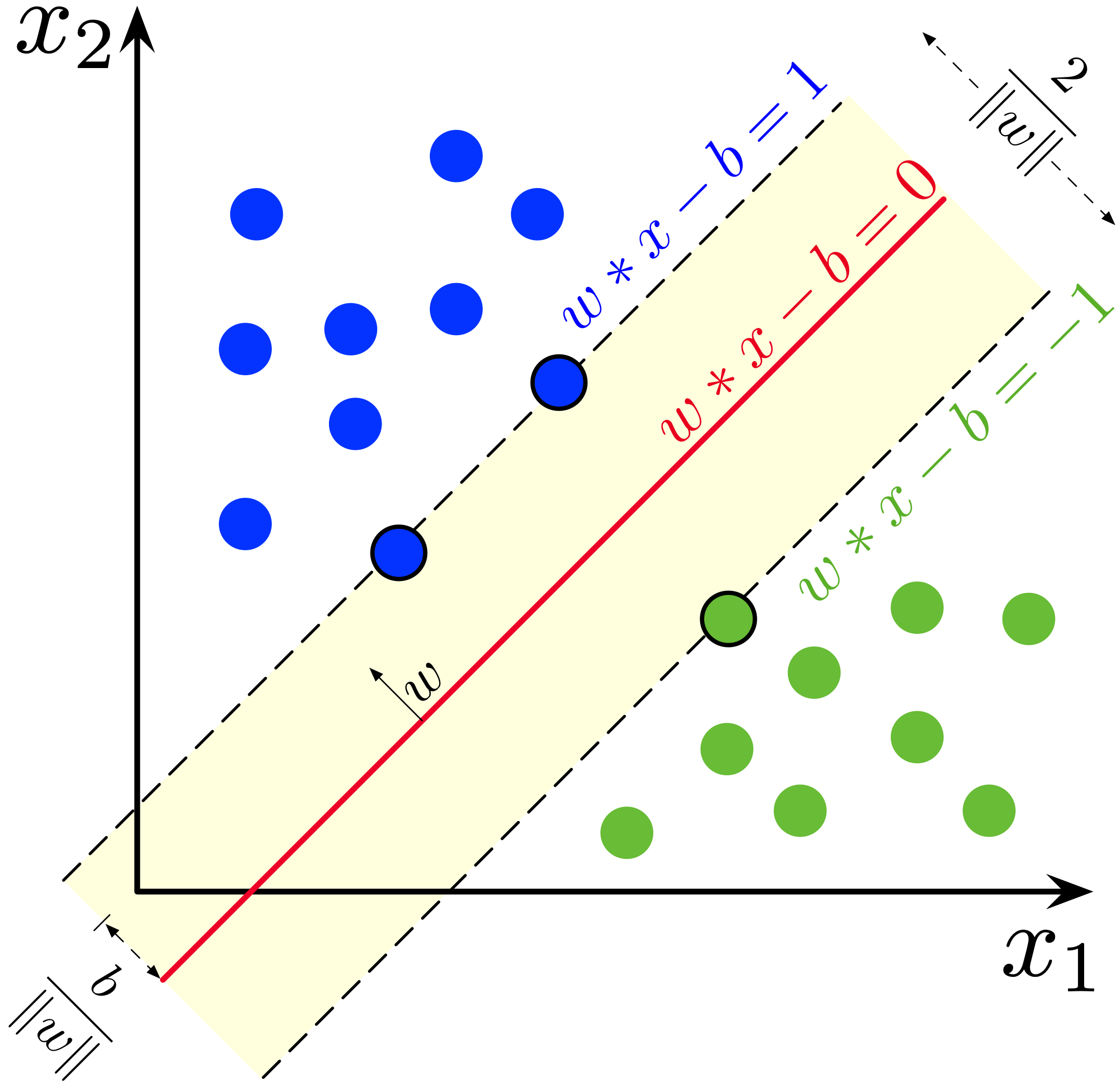
- Figure 1: A hyperplane separating two classes with support vectors marked
- Kernel Trick
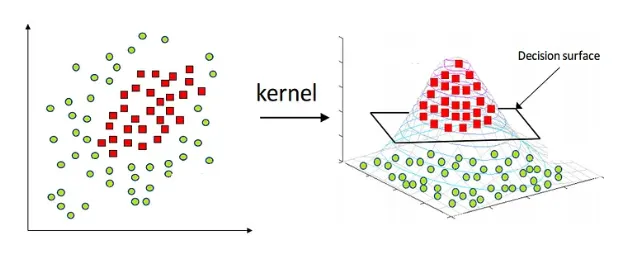
- Figure 2: Transformation of non-linearly separable data using kernel trick
Conclusion
Support Vector Machines are a versatile and powerful tool in the machine learning toolbox. Whether you’re dealing with high-dimensional data or complex classification tasks, understanding and implementing SVM can significantly enhance the performance of your models. By mastering SVM, you’ll be equipped to tackle a wide range of practical machine learning challenges.